We work on making our research apps as robust and error-tolerant as possible. Yet, some bugs in input data will always require the intervention of the user. For example, our apps can not fill data gaps. On this page, we list the most common bugs, provide illustrative screenshots, and explain how to fix the files.
How your files should look like
Before looking at the most common bugs, let's first have a look at what your files should look like. See screenshots of the sample data below, opened in a text editor, such as Microsoft Window's NotePad:
| 01_RequestFile |
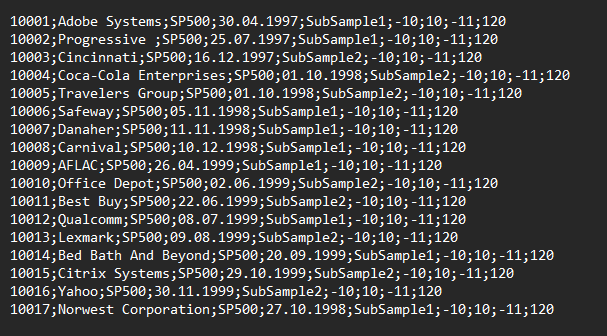 |
| 02_FirmData | 03_MarketData |
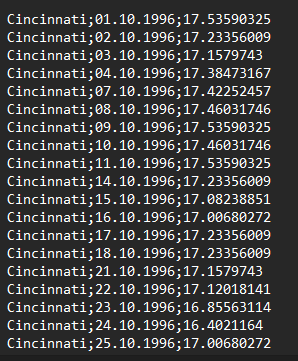 |
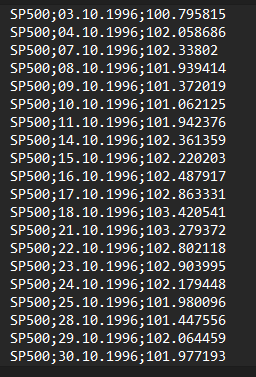 |
If you open your input files in the text editor and they look different, the abnormal return calculators will likely not perform the analysis and display an error message that guides you to the first error the app encounters when loading the data.
It is crucial that you use identical syntax for the firm and index names across all three files. The Request File steers the analysis and then links the data from the other two files. If you use mismatching syntax, the data will not be merged as required for the analysis.
Further, please note that some errors do not fail the overall analysis (e.g., misspecified event windows) but lead to skipped events/instances. You find these cases listed in the "overarching comment"-section of the Analysis Report file.
The Most Common Bugs:
#1 Bug: Commas used instead of semicolons as column separators
|
Example of the bug:
|
Why this issue arises: Excel or any other spreadsheet software typically inherits a local scheme for separators and date formats from your system settings. When you store your file in CSV format, the spreadsheet software may place commas (e.g., in Germany). EST ARC requires semicolons because commas are also often part of company names or are also used as a decimal separator. |

The fix: Use your text editor's function to replace all commas with semicolons.
#2 Bug: Wrong date formats
|
Example of the bug:
|
Why this issue arises: Wrong date formats are a common error, for two main reasons: First, date conventions vary across countries, and spreadsheet software thus saves according to the local schemes. Second, sometimes dates are not recognized correctly in the spreadsheet program - when then stored as CSV, the date gets recorded as a number (see the third example in the picture on the left). EST ARC allows two date formats: DD.MM.YYYY and YYYY-MM-DD. |

The fix: There are two options if you have the wrong local scheme. Either change the local date scheme in your spreadsheet program or create the date string not as format date but as format text - for this, if you use Excel, use the formula concat().
#3 Bug: Duplicate data in firm or market files
|
Example of the bug:
|
Why this issue arises: This issue may arise when you combine multiple data time series of one index or firm - which may be needed if you have multiple events of the same firm/index in your sample. EST does not allow for duplicate data since it cannot decide which of the entries should be the right one. A duplicate is two lines of one index/firm and date combination - with the same or different prices (see screenshots on the left). Both cases will corrupt ARC. |
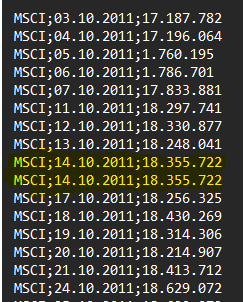

The fix: For fixing this bug, you will need your spreadsheet software. In MS Excel, for example, you can mark the data (company/index name and date) in your input files and select the function "delete duplicates". Please note that for a single company or index, there cannot be more than one closing price in one day.
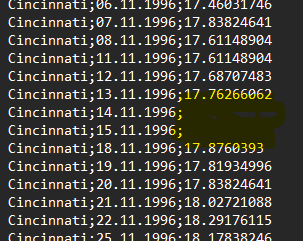
#4 Data Gaps: Missing data that cannot be filled
|
Example of the bug:
or
|
Why this issue arises: The data from your data provider may have gaps. The first example on the left shows the Market Data file for the Fama-French 5-Factor Model of a recent user. Instead of closing prices, it holds the text value "NULL" in several instances within the price vector. The second example on the left was fabricated using the Firm Data file from our sample dataset. ARC cannot interpret text inputs where it expects numbers, nor can it fill gaps of data. It will prompt you a corresponding error message. |

Data bugs for which our import mechanism now automatically corrects:
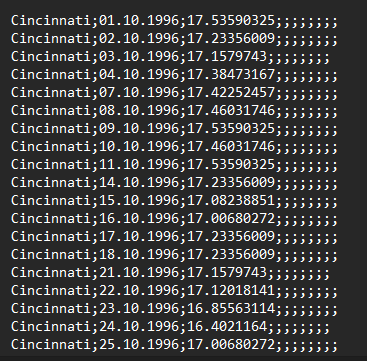
Random commas or semicolons at the end of your input file
|
Example of the bug:
|
Why this issue arises: When editing data in Excel or any other spreadsheet software, one regularly copies around whole columns and deletes some. When you then store your file in CSV format, the spreadsheet software often keeps those deleted/empty columns in your file. EST ARC then finds more than the required 3 columns in the input files and has issues with reading your inputs. |
The fix: Use your text editor's function and replace all occurrences of multiple commas or semicolons next to each other with nil/nothing - this factually deletes all unneeded commas/semicolons. Since there is no find & delete in most editors, you need to find & replace.